|
Центральным понятием в области баз данных является понятие модели. Модель данных — это некоторая абстракция, которая, будучи приложима к конкретным данным, позволяет пользователям и разработчикам трактовать их уже как информацию, то есть сведения, содержащие не только данные, но и взаимосвязь между ними. В соответствии с рассмотренной ранее трехуровневой архитектурой приходится сталкиваться с понятием модели данных по отношению к каждому уровню
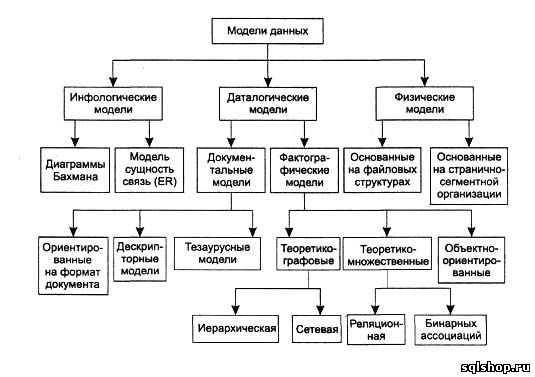
Инфологические модели используются на ранних стадиях проектирования баз данных для формального описания предметной области. Они содержат информацию о классах объектов, их свойствах и взаимосвязях, описания структур данных без привязки к какой-либо конкретной СУБД. Инфологические (или семантические) модели отражают в естественной и удобной для разработчиков и других пользователей форме информацию о предметной области в процессе разработки структуры будущей базы данных. Физическая модель данных оперирует категориями, касающимися организации внешней памяти и структур хранения, используемых в данной операционной среде. В настоящий момент в качестве физических моделей используются различные методы размещения данных, основанные на файловых структурах: это организация файлов прямого и последовательного доступа, индексных файлов и инвертированных списков. Кроме того, современные СУБД широко используют страничную организацию данных. В этом случае база данных представлена минимальным количеством файлов, а задачи поиска, чтения и записи данных выполняет сама СУБД, а не операционная система. Физические модели данных, основанные на страничной организации, являются наиболее перспективными. Наибольший интерес вызывают модели данных, используемые на концептуальном уровне. По отношению к ним внешние модели называются подсхемами и используют те же абстрактные категории, что и концептуальные модели данных. Даталогические модели являются моделями концептуального уровня и разрабатываются для конкретной СУБД. Документальные модели данных соответствуют представлению о слабоструктурированной информации, ориентированной в основном на свободные форматы документов, текстов на естественном языке. Модели, ориентированные на формат документов, связаны прежде всего со стандартным общим языком разметки — SGML (Standart Generalised Markup Language), который был утвержден ISO в качестве стандарта еще в 80-х годах. Этот язык предназначен для создания других языков разметки, он определяет допустимый набор тегов (ссылок), их атрибуты и внутреннюю структуру документа. Контроль за правильностью использования тегов осуществляется при помощи специального набора правил, которые используются программой клиента при разборе документа. Для каждого класса документов определяется свой набор правил, описывающих грамматику соответствующего языка разметки. Гораздо более простой и удобный, чем SGML, язык HTML (HyperText Markup Language – язык разметки гипертекста) позволяет определять оформление элементов документа и имеет некий ограниченный набор инструкций — тегов, при помощи которых осуществляется процесс разметки. Инструкции HTML в первую очередь предназначены для управления процессом вывода содержимого документа на экране программы-клиента и определяют этим самым способ представления документа, но не его структуру. В качестве элемента гипертекстовой базы данных, описываемой HTML, используется текстовый файл, который может легко передаваться по сети с использованием протокола HTTP. В настоящее время все большую популярность приобретает язык XML (eXtensible Markup Language – расширяемый язык разметки), позволяющий описывать документы произвольной структуры и содержания. Тезаурусные модели основаны на принципе организации словарей. Они содержат определенные языковые конструкции и принципы их взаимодействия в заданной грамматике. Эти модели эффективно используются в системах-переводчиках, особенно многоязыковых. Принцип хранения информации в этих системах и подчиняется тезаурусным моделям. Дескриптпорные модели — самые простые из документальных моделей, они широко использовались на ранних стадиях использования документальных баз данных. В этих моделях каждому документу соответствовал дескриптор — описатель. Этот дескриптор имеет жесткую структуру и описывает документ в соответствии с теми характеристиками, которые требуются для работы с документами в разрабатываемой документальной базе данных. Например, для БД, содержащей описание патентов, дескриптор содержит название области, к которой относился патент, номер патента, дату выдачи патента и еще ряд ключевых параметров, которые заполнялись для каждого патента. Обработка информации в таких базах данных ведется исключительно по дескрипторам, то есть по тем параметрам, которые характеризуют патент, а не по самому тексту патента. Теоретико-графовые модели отражают совокупность объектов реального мира в виде графа взаимосвязанных информационных объектов. Математической основой таких моделей является теория графов. Реляционная модель будет подробно рассмотрена далее. | |
|
| |
| Просмотров: 24758 | |
| Всего комментариев: 0 | |